Lab Meeting March 2026
The Data Donation Lab is hosting its next online Lab Meeting on 26 March from 12:00 to 13:00 (Zurich Time). The session will feature two invited talks and updates on current Lab activities.
Guest Lectures
Sebastian Prechsl
LMU & Institute for Employment Research
Participation in Data Donation Studies: Experimental Evidence on Framing and Motivational Appeals
Authors: Sebastian Prechsl, Frieder Rodewald, Florian Keusch, Valerie Hase, Frauke Kreuter, Mark Trappmann
We experimentally tested two strategies to boost participation in a pre-registered study with over 2000 YouTube, Instagram or LinkedIn users from Germany: we varied (1) how we invited people, either framing the study as a web survey or directly describing it as a data donation study, and (2) the motivational appeals highlighting either prosocial advantages or personal gains from donating data. We found that neither study framing nor motivational appeals significantly affected people's willingness to donate data or their actual donation rates. However, framing the study from the start as data donation research led to significantly more people starting the study. Our results demonstrate that researchers need to consider how they design invitations to data donation studies, while revealing that study framing or motivational appeals fail to increase respondents' willingness to donate or their actual donation behavior.

Lukas Tribelhorn
University of Zurich
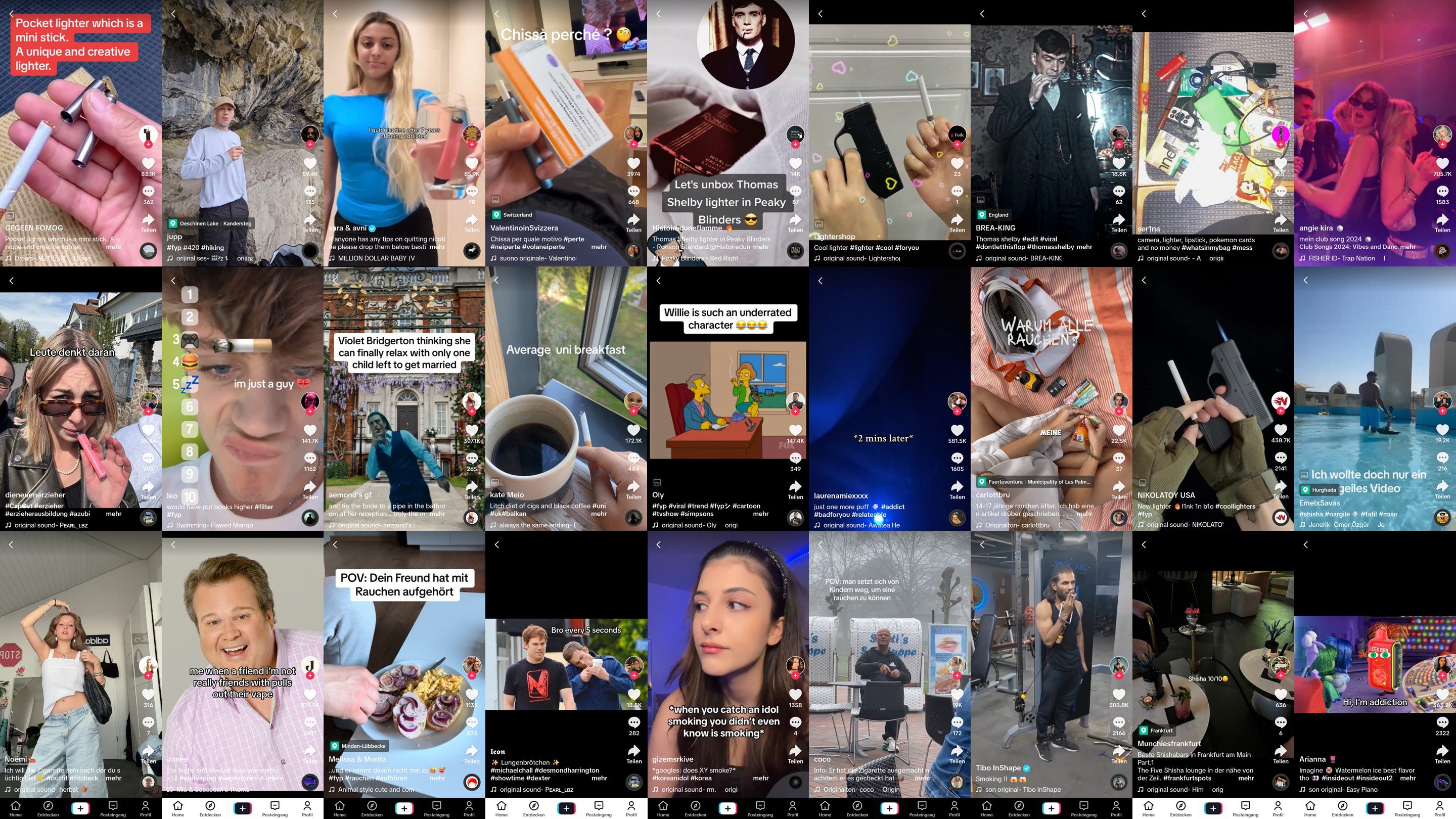
Smoking Cues on TikTok: Detecting and Measuring the Prevalence of Smoking-Related Content in Users Feeds
Authors: Lukas Tribelhorn, Lion Wedel, Thomas Friemel
Studies of the prevalence or characteristics of problematic social media content, such as smoking or vaping content, often rely on keyword-based sampling approaches or convenience samples. Taking a more user-centric approach, we collected digital trace data from 230 adolescents and young adults. In a second step, we then attempted to collect metadata and audiovisual data of all 3.8 million unique posts seen by users in our sample. The resulting corpus of 2.8 million posts was explored in two directions: 1.) We pulled a large sample for manual content analysis, and 2.) We employed a multimodal large language model to classify the full corpus. In our presentation, we will present additional information on our methodology as well as preliminary results.
Meeting Access
The meeting is open to all interested participants.
Zoom link: https://uzh.zoom.us/j/62779500422?pwd=UQt20ErFsS0YdqvmHfZMSBFvRSUEUc.1
Meeting-ID: 627 7950 0422
Passcode: 362795
